- História do Desenvolvimento do Projeto LegiNote 1 - A Ideia
- A StatPan iniciou o projeto LegiNote com o objetivo de aumentar a acessibilidade às propostas de lei e atas do parlamento, além de melhorar a eficiência legislativa por meio da IA.
Olá, sou o StatPan.
Estou escrevendo sobre o desenvolvimento do projeto paralelo LegiNote.
Para a parte anterior, consulte o seguinte link.
Arquitetura Básica
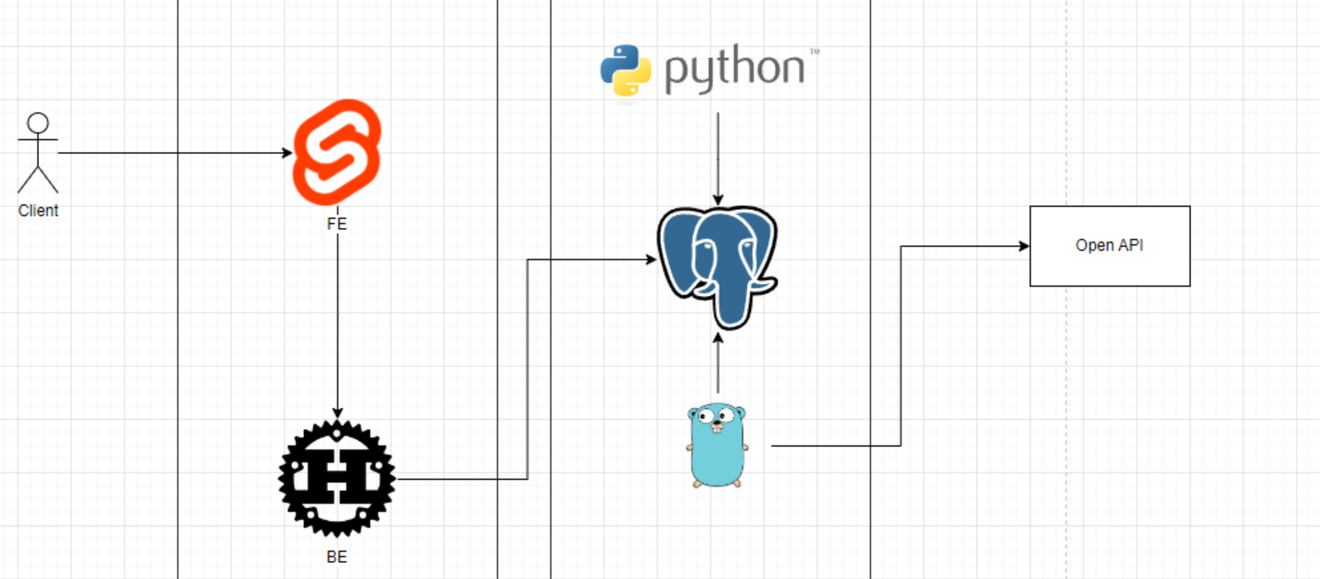
Cortesia de 태양토끼님 (taeyangtokki) Design do Leginote
O Leginote será desenvolvido inicialmente como um serviço web, com a seguinte pilha de tecnologias:
Frontend: Svelte
Backend: Rust (estamos considerando seriamente o rupring, mas isso pode mudar)
Worker: Go (buscando o uso extremo de std, excluindo dependências obrigatórias)
Análise de Dados: Python (desde o pré-processamento até a integração futura de inteligência artificial)
Dentre as tecnologias listadas, pretendo focar no desenvolvimento das partes Worker e Análise de Dados, que são as áreas em que contribuo principalmente. As publicações deste diário de desenvolvimento se concentrarão nessas áreas.
Vamos começar com a história do Worker.
Worker
Escolha da Linguagem

logo golang
Comecei a programar em Python e, como atualmente trabalho na área de ciência de dados, a linguagem Python é a que mais domino. No entanto, como apenas dominava linguagens de script, comecei a ter o desejo por uma linguagem compilada robusta, o que me levou a me interessar por Go e Rust.
Em particular, Rust era a linguagem que eu mais acompanhava ultimamente, e ela costumava ser mencionada juntamente com C++ e Golang. (Embora C++ seja uma linguagem excelente, a excluí do desenvolvimento de serviços de rede neste caso. Não sei se vou precisar trabalhar diretamente com ela no futuro, a menos que precise lidar com o interior de um framework de deep learning.)
Aprendi Rust e Golang, utilizei-as para fazer solicitações de rede simples e identifiquei os prós e contras de cada uma. Acho que seria muito longo detalhar os prós e contras de cada uma neste texto, então seria melhor fazer um resumo separado em outro texto. Resumindo,
Para um projeto desconhecido, em que não sabemos se teremos receita, e que pode ser configurado sem dependências adicionais na área de rede, Golangfoi a linguagem escolhida.
Função do Worker
Tela OpenAPI
A função do Worker é coletar e atualizar dados periodicamente por meio de sites OpenAPI. Podemos dividi-la em três partes:
1. Configurar a lógica de coleta para informações específicas
2. Configurar um executor para executar a lógica de coleta
3. Carregar os dados coletados no banco de dados
O objetivo é aplicar e expandir o mesmo procedimento para vários conjuntos de dados de API.
Plano de Estrutura do Projeto
Existem várias arquiteturas possíveis para a estrutura do projeto, e o uso de um framework pode nos ajudar a iniciar o projeto com uma estrutura já definida. No entanto, como mencionado anteriormente, o objetivo deste projeto é minimizar as dependências durante o desenvolvimento, por isso optamos por organizar as pastas de acordo com as funções definidas para cada uma, para ficar o mais próximo possível da lógica definida.
O projeto será estruturado da seguinte forma:
leginote-worker-bill/
├── main.go
├── api/
│ └── client.go
├── db/
│ ├── connection.go
│ └── repository.go
├── util/
│ ├── error.go
│ └── runner.go
│ └── config.go
├── worker/
│ └── worker.go
├── go.mod
└── go.sum
api - A coleta de dados é realizada por meio de OpenAPI de dados públicos. Portanto, o código básico para comunicação com a OpenAPI estará localizado na pasta api. Atualmente, apenas uma API é usada como principal, então a estrutura consiste em apenas um arquivo de cliente.
db - A lógica de comunicação com o banco de dados é definida aqui. O código dentro de connection é responsável apenas pela conexão, e o repositório contém a lógica para executar vários comandos SQL upsert. A inclusão do próprio SQL no código é muito complexa, então pretendo mover o SQL para um arquivo separado no futuro.
util - Aqui estão definidas várias lógicas que auxiliam as tarefas. O error é um script temporário criado para lidar com o resultado de erro retornado pelo Go. Como veremos mais adiante, isso terá um grande efeito borboleta (?).
O arquivo config lê o arquivo .env e, para evitar o uso de um pacote separado para essa finalidade, ele contém uma função definida para ler o arquivo .env.
worker - É o local onde está a lógica principal que utiliza as lógicas api e db para criar o comportamento desejado. Quando houver mais tipos de worker, ele precisará ser expandido da mesma forma. No entanto, por enquanto, ele contém apenas a lógica do comportamento principal de um worker.
Pretendo continuar desenvolvendo o código de forma que os princípios da arquitetura em camadas sejam mantidos.
Dependências do Projeto
pq para uso do Postgres
sqlx para uso de consultas
Conclusão do Worker
Acho que só listar a teoria sem código pode ser um pouco chato, e também estou começando a ficar um pouco entediado, então acho que vou finalizar rapidamente.
Esta é o fim da Parte 2. Espero que na Parte 3 eu possa trazer um pouco de código para tornar a discussão mais interessante.
Durante o desenvolvimento do LegiNote, se você tiver algum recurso que considere necessário ou alguma dúvida sobre o desenvolvimento, sinta-se à vontade para deixar um comentário!
Comentários0