- Historia rozwoju projektu LegiNote 1 - Pomysł
- StatPan rozpoczął projekt LegiNote z myślą o zwiększeniu dostępności do projektów ustaw i protokołów posiedzeń parlamentu oraz wykorzystaniu sztucznej inteligencji do poprawy efektywności procesu legislacyjnego.
Dzień dobry, jestem StatPan.
Piszę o rozwoju projektu pobocnego LegiNote.
Aby zapoznać się z poprzednią częścią, proszę skorzystać z poniższego linku.
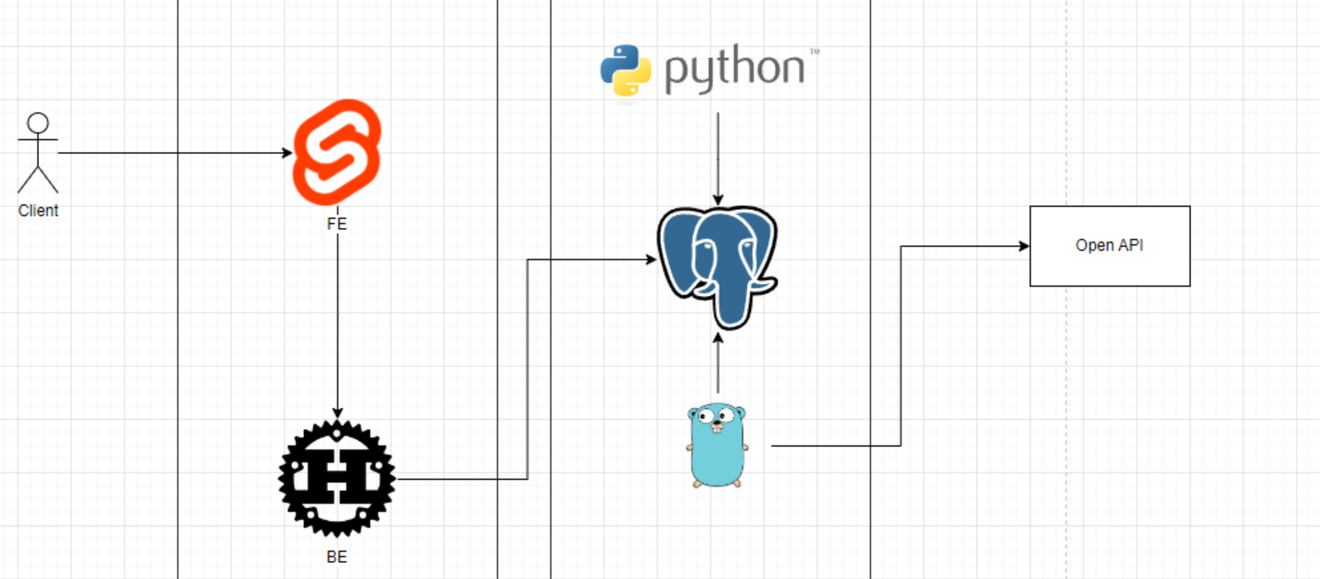
Podstawowa architektura
Projekt Leginote – wsparcie od TaeYangTokki
Leginote jest projektowany przede wszystkim jako usługa internetowa, dlatego planujemy użyć następującego stosu technologicznego.
Frontend: Svelte
Backend: Rust (bardzo rozważamy użycie rupring, ale może się to zmienić)
Worker: Go (dążymy do ekstremalnego wykorzystania std, z wyłączeniem niezbędnych zależności)
Analiza danych: Python (od przetwarzania wstępnego, aż po późniejszą integrację z sztuczną inteligencją)
W ramach powyższego stosu, zamierzam skupić się na rozwoju części Worker i Analizy Danych, co będzie głównym tematem moich wpisów w tym cyklu.
Na początek przyjrzyjmy się Workerowi.
Worker
Wybór języka

logo golang
Zacząłem programować w Pythonie, a moje obecne główne zajęcie to Data Science, więc ten język jest mi najbardziej znany. Jednak mając doświadczenie tylko w językach skryptowych, zacząłem pragnąć solidnego języka kompilowanego, co doprowadziło mnie do zainteresowania się Go i Rust.
Szczególnie w ostatnim czasie z dużym zainteresowaniem śledziłem Rust, który często wymieniany jest w kontekście C++ i Golang. (Oczywiście C++ jest również świetnym językiem, ale w przypadku tego typu rozwoju usług sieciowych pominąłem go. Na razie nie jestem pewien, czy będę go używał w przyszłości, chyba że zajmę się wewnętrzną częścią frameworków uczenia maszynowego).
Ucząc się Rust i Golang oraz eksperymentując z nimi w kontekście prostych żądań sieciowych, zdołałem krótko scharakteryzować ich wady i zalety. Szczegółowe porównanie zalet i wad obu języków sprawiłoby, że ten wpis byłby zbyt długi, więc lepiej będzie to omówić osobno w innej części. W skrócie,
w kontekście rozwoju w dziedzinie sieci, możliwość skonfigurowania bez dodatkowych zależności oraz fakt, że nie wiadomo, czy projekt przyniesie jakiekolwiek dochody, spowodowały, żeGolangzostał wybrany jako język do tego projektu.
Rola Workera
Ekran OpenAPI
Rolą Workera jest regularne pobieranie i aktualizowanie danych za pośrednictwem strony OpenAPI. Można ją podzielić na trzy części:
1. Ustawienie logiki pobierania dla określonych informacji
2. Ustawienie mechanizmu uruchamiającego logikę pobierania
3. Załadowanie zebranych danych do bazy danych
Celem jest rozszerzenie tego samego procesu na różne dane API poprzez zastosowanie tych samych trzech kroków.
Sposób organizacji projektu
Istnieje wiele różnych architektur do organizacji projektu, a w szczególności użycie frameworka pozwala na rozpoczęcie projektu z gotową strukturą. Jednak, jak wspomniałem wcześniej, celem tego projektu jest minimalizacja zależności, dlatego chciałem, aby struktura projektu była jak najbardziej zbliżona do zdefiniowanej wcześniej logiki, a funkcje były rozdzielone do różnych folderów.
Projekt będzie zorganizowany w następujący sposób:
leginote-worker-bill/
├── main.go
├── api/
│ └── client.go
├── db/
│ ├── connection.go
│ └── repository.go
├── util/
│ ├── error.go
│ └── runner.go
│ └── config.go
├── worker/
│ └── worker.go
├── go.mod
└── go.sum
api - Pobieranie danych odbywa się za pośrednictwem publicznego API OpenAPI. Podstawowy kod komunikacji z OpenAPI znajduje się w folderze api. Obecnie używamy tylko jednego głównego API, więc struktura składa się tylko z jednego pliku klienta.
db - Znajduje się tu logika komunikacji z bazą danych. Kod w connection odpowiada tylko za połączenie, a w repository znajdują się różne instrukcje SQL do wstawiania lub aktualizowania danych. Umieszczanie samego kodu SQL w kodzie jest zbyt skomplikowane, dlatego w przyszłości planuję przenieść SQL do osobnych plików.
util - Znajduje się tu wiele różnych funkcji pomocniczych. error to tymczasowy skrypt do wygodnego obsługiwania wyników błędów zwracanych przez Go. Później, w kolejnych częściach tego cyklu, zobaczymy, że ten skrypt ma ogromny wpływ na projekt (?).
Plik config służy do odczytywania pliku .env. Zamiast używać osobnego pakietu, zdefiniowałem funkcję odczytu .env bezpośrednio w tym pliku.
worker - Zawiera główną logikę, która wykorzystuje logikę api i db do osiągnięcia pożądanego rezultatu. Później, gdy pojawią się nowe rodzaje workerów, ta struktura prawdopodobnie również będzie musiała się rozszerzyć, ale na razie zawiera tylko jedną główną funkcję workera.
W przyszłości planuję rozwijać kod w taki sposób, aby zachować zasadę architektury warstwowej.
Zależności projektu
pq do pracy z PostgreSQL
sqlx do obsługi zapytań
Podsumowanie Workera
Wydaje mi się, że samo wymienianie teorii bez kodu jest nudne, a i ja sam czuję się trochę zmęczony, więc podsumuję to dość szybko.
To już koniec drugiej części. Mam nadzieję, że w trzeciej części będę mógł przedstawić więcej kodu i kontynuować dyskusję.
W trakcie rozwoju Leginote, jeśli macie jakieś pomysły na funkcje, które Waszym zdaniem są potrzebne, lub macie jakieś pytania dotyczące rozwoju, zapraszam do komentowania!
Komentarze0