- LegiNoteプロジェクト開発物語1 - アイデア
- StatPanは、国会法案および議事録へのアクセス性を高め、AIを活用した立法効率向上を目指してLegiNoteプロジェクトを開始しました。
こんにちは、StatPanです。
LegiNoteのサイドプロジェクトの開発記を書いています。
以前の記事は、次のリンクを参照してください。
基本アーキテクチャ
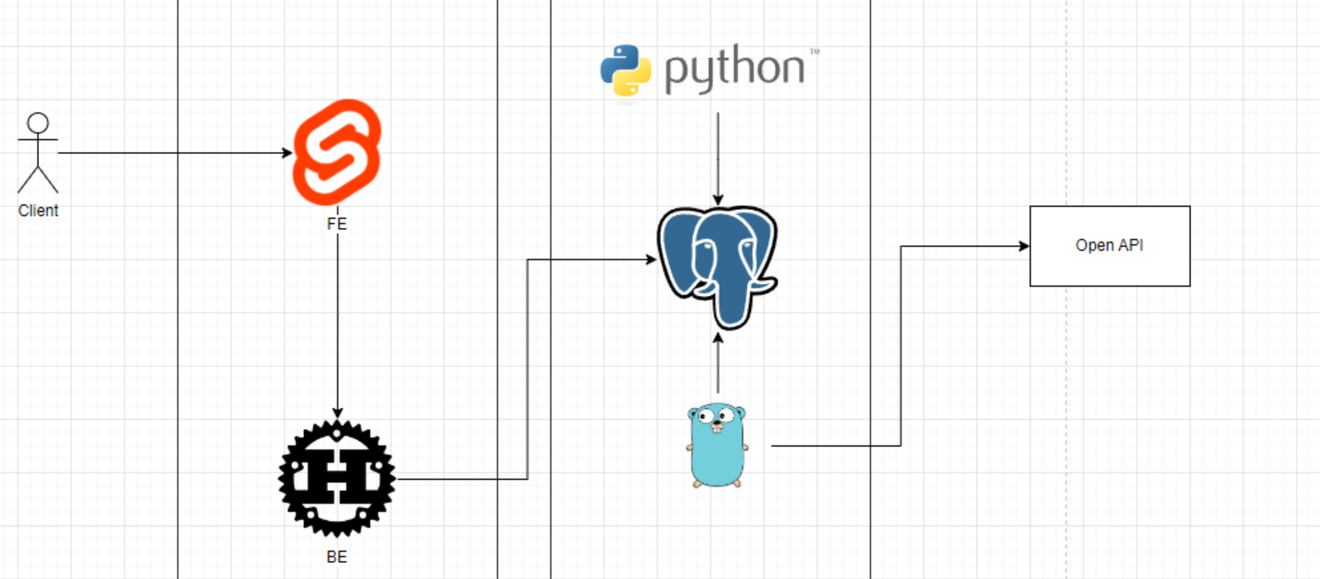
太陽토끼님(テヤントッキニム)提供 Leginote設計
Leginoteは、まずWebサービスとして開発されることを念頭に置いて、以下のテクノロジースタックを使用する予定です。
フロントエンド: Svelte
バックエンド: Rust(rupringを強く検討していますが、変更される可能性があります)
ワーカー: Go(必須の依存関係を除き、stdの極限の使用を目指します)
データ分析: Python(前処理から、将来的には人工知能の導入まで)
上記のスタックの中で、私が重点的に貢献する領域であるワーカーとデータ分析の部分を中心に開発記を連載予定です。
まずはワーカーについてお話しましょう。
ワーカー
言語の選択

golangロゴ
私はPythonでプログラミングを始め、現在も業務のメインがデータサイエンス分野であるため、Python言語に最も精通しています。しかし、スクリプト言語しか知らなかった私は、堅牢なコンパイル言語への欲求を持つようになり、GoとRust言語に興味を持つようになりました。
特に最近、最も注目して見ていた言語がRustでした。Rustは、代表的にC++やGolangと一緒に言及されることが多いです。(もちろんC++も優れた言語ですが、このようなネットワーク関連サービス開発では除外しました。今後、ディープラーニングフレームワーク内部を扱うのでない限り、直接扱うかどうかはよく分かりません)
このようにRustとGolangを学習し、簡単なネットワークリクエストで使用してみることで、Rustの長所と短所、Golangの長所と短所を簡単に把握しました。この記事で両者の長所と短所を議論するのは、記事が長くなってしまうため、別の記事でまとめるのが良いと考え、ここでは簡単に触れるだけにします。
ネットワーク分野で追加の依存関係なしに構成可能であり、収益が発生するかどうか分からない未知のプロジェクトを進めるには、Golangを使用することにしました。
ワーカーの役割
OpenAPI画面
ワーカーの役割は、定期的にOpenAPIサイトを通じてデータを収集・更新することで、次の3つに分けられます。
1. 特定の情報について収集ロジックを設定する
2. 収集ロジックを実行するランナーを設定する
3. 収集データをDBに格納する
上記の3つの同じ手順を、さまざまなAPIデータに同じように適用し、拡張していくことが目標です。
プロジェクト構成案
プロジェクトの構成には、さまざまなアーキテクチャが存在し、特にフレームワークを使用すると、プロジェクト開始から構造化された状態で開始できます。ただし、前述のように、今回のプロジェクトでは依存関係を最小限に抑えて開発することを目標としているため、上記で定義したロジックの実装に近づけ、機能ごとにフォルダを分割することにしました。
プロジェクトは以下の構成になります。
leginote-worker-bill/
├── main.go
├── api/
│ └── client.go
├── db/
│ ├── connection.go
│ └── repository.go
├── util/
│ ├── error.go
│ └── runner.go
│ └── config.go
├── worker/
│ └── worker.go
├── go.mod
└── go.sum
api - データ収集は、公開データOpenAPIを通じて行います。そのため、OpenAPIと通信する基本的なコードはapiフォルダ以下に配置されます。現時点では、1つのAPIのみをメインで使用するため、1つのクライアントファイルのみで構成されています。
db - DBと通信するロジックが定義されています。connection内部のコードは接続のみを担当し、repositoryにはさまざまなupsert SQLを格納して実行するロジックがあります。SQL自体がコードに含まれているのは、やはり複雑すぎるため、SQLは今後別ファイルに作成する予定です。
util - 作業中に機能を補助するさまざまなロジックを定義した場所です。errorは、Goで発生するerror resultを簡単に処理するために、一時的に作成したスクリプトです。後の開発記の内容でわかると思いますが、これが非常に大きなバタフライ効果の原因になります(?)。
configファイルは、.envファイルを読み込む際に、別のパッケージを使用せずに、.envファイルを読み込む関数を直接定義したファイルです。
worker - apiおよびdbのロジックを適切に使用して、目的の動作を実現する主要なロジックが格納されている場所です。将来的にワーカーの種類が増えると、同様に増える必要があると思いますが、現時点では1つのメインワーカー動作のみが含まれています。
今後、レイヤードアーキテクチャの原則を守った状態でコードを進化させていく予定です。
プロジェクトの依存関係
postgresの使用のためのpq
クエリ使用のためのsqlx
ワーカーのまとめ
コードなしで理論だけを並べるのは、面白くないかもしれないし、私自身も少しダレてきたように感じています。そのため、少し早めにまとめに入ります。
すでに第2回は終わりです。第3回からは、コードを1行でも多く紹介して、話を進めていきたいと思っています。
レジノートの開発中に、必要だと思う機能があれば、または開発について質問があれば、いつでもコメントしてください!
コメント0