- लेगीनोट प्रोजेक्ट विकास की कहानी 1 - आइडिया
- स्टेटपैन ने लेगीनोट प्रोजेक्ट की शुरुआत संसदीय विधेयक और बैठक के रिकॉर्ड तक पहुंच को बढ़ाने और एआई का उपयोग करके विधायी दक्षता में सुधार के लक्ष्य के साथ की है।
नमस्ते स्टेटपैन हूँ।
लेगिनोट साइड प्रोजेक्ट के डेवलपमेंट स्टोरी को लिख रहा हूँ।
पिछले भाग के लिए, कृपया निम्नलिखित लिंक देखें।
बेसिक आर्किटेक्चर
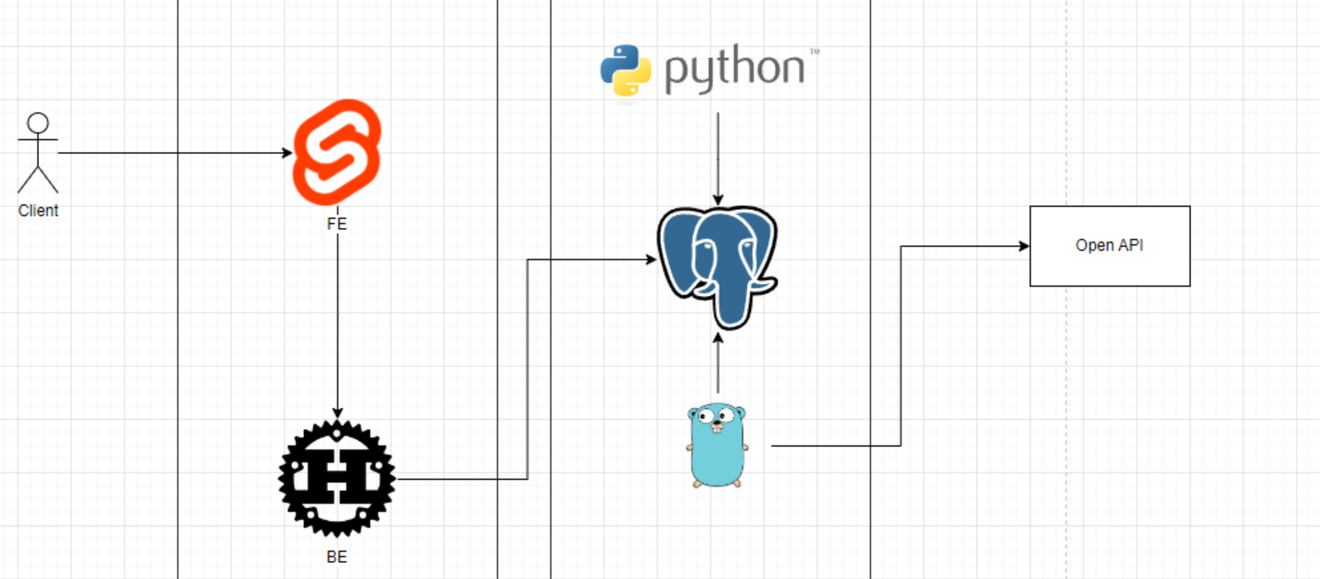
태양토끼님 협찬 Leginote 설계
लेगिनोट को मुख्य रूप से एक वेब सेवा के रूप में विकसित करने के विचार के साथ, हम निम्नलिखित तकनीकी स्टैक का उपयोग करने वाले हैं।
फ्रंटएंड: स्वेल्ट
बैकएंड: रस्ट (हम रस्टपिंग पर बहुत ध्यान दे रहे हैं, लेकिन यह बदल सकता है)
वर्कर: गो (अतिरिक्त निर्भरता को छोड़कर, हम मानक लाइब्रेरी के उपयोग पर ध्यान केंद्रित करेंगे)
डेटा विश्लेषण: पायथन (पूर्व-संसाधन से लेकर भविष्य में कृत्रिम बुद्धिमत्ता के एकीकरण तक)
उपरोक्त स्टैक में से, मैं वर्कर और डेटा विश्लेषण भागों पर ध्यान केंद्रित करने जा रहा हूं, जो कि मेरे योगदान के मुख्य क्षेत्र हैं, और मैं डेवलपमेंट स्टोरी को इसी क्रम में जारी रखूंगा।
सबसे पहले, आइए वर्कर के बारे में बात करते हैं।
वर्कर
भाषा का चुनाव

golang logo
मैंने पायथन से प्रोग्रामिंग शुरू की थी, और चूँकि मेरा वर्तमान मुख्य काम डेटा साइंस का है, इसलिए मैं पायथन भाषा से सबसे अधिक परिचित हूँ। हालाँकि, केवल स्क्रिप्टिंग भाषाओं को जानने के बाद, मुझे एक मजबूत संकलित भाषा के प्रति लालसा हो गई, और इसलिए मेरी रुचि गो और रस्ट भाषाओं में बढ़ी।
विशेष रूप से, हाल के दिनों में, रस्ट ऐसी भाषा रही है जिस पर मैंने सबसे अधिक ध्यान दिया है, और जब रस्ट का उल्लेख किया जाता है, तो अक्सर सी++ और गोलैंग का भी उल्लेख किया जाता है। (हालांकि सी++ भी एक उत्कृष्ट भाषा है, हमने इसे इस तरह की नेटवर्क सेवा विकास परियोजनाओं से बाहर रखा है। मुझे यकीन नहीं है कि क्या मैं इसे भविष्य में सीधे उपयोग करूंगा जब तक कि हम डीप लर्निंग फ्रेमवर्क के आंतरिक कामकाज को नहीं संभाल रहे हैं।)
इस तरह, मैंने रस्ट और गोलैंग सीखा और सरल नेटवर्क अनुरोधों में उनका उपयोग किया, जिससे मैं रस्ट के फायदे और नुकसान और गोलैंग के फायदे और नुकसान को समझ सका। इस लेख में उन दोनों के फायदे और नुकसान की तुलना करना बहुत लंबा हो जाएगा, इसलिए मैं इसे संक्षेप में रखूंगा और बाद में एक अलग लेख में इसे विस्तार से बताऊंगा।
नेटवर्क क्षेत्र में, अतिरिक्त निर्भरता के बिना कॉन्फ़िगर करने योग्य और एक अज्ञात परियोजना के लिए जिसके लिए यह सुनिश्चित नहीं है कि क्या राजस्व उत्पन्न होगा,गोलैंगका उपयोग करने का फैसला किया गया है।
वर्कर की भूमिका
OpenAPI स्क्रीन
वर्कर की भूमिका हर अवधि में ओपनएपीआई साइट से डेटा एकत्र करना और उसे अपडेट करना है, और इसे तीन भागों में विभाजित किया जा सकता है।
1. विशिष्ट जानकारी एकत्र करने के लिए तर्क सेट करना
2. एकत्र किए गए डेटा को चलाने के लिए एक रनर सेट करना
3. एकत्रित डेटा को डीबी में लोड करना
उद्देश्य विभिन्न एपीआई डेटा के लिए ऊपर दिए गए तीन चरणों की समान प्रक्रिया को लागू करना और इसे विस्तारित करना है।
प्रोजेक्ट संरचना योजना
प्रोजेक्ट संरचना के लिए कई अलग-अलग आर्किटेक्चर हैं, और विशेष रूप से, यदि आप एक फ्रेमवर्क का उपयोग करते हैं, तो आप प्रोजेक्ट की शुरुआत एक संरचित अवस्था में कर सकते हैं। हालांकि, जैसा कि ऊपर उल्लेख किया गया है, इस परियोजना का लक्ष्य निर्भरताओं को कम से कम रखना है, इसलिए हमने प्रत्येक फ़ंक्शन को फ़ोल्डरों में विभाजित करने का लक्ष्य रखा है, जो ऊपर परिभाषित तर्क के कार्यान्वयन के करीब है।
प्रोजेक्ट इस प्रकार संरचित है।
leginote-worker-bill/
├── main.go
├── api/
│ └── client.go
├── db/
│ ├── connection.go
│ └── repository.go
├── util/
│ ├── error.go
│ └── runner.go
│ └── config.go
├── worker/
│ └── worker.go
├── go.mod
└── go.sum
api - डेटा संग्रह सार्वजनिक डेटा ओपनएपीआई के माध्यम से किया जाता है। इसलिए, ओपनएपीआई के साथ संवाद करने के लिए मूल कोड api फ़ोल्डर के अंतर्गत आएगा। वर्तमान में, केवल एक एपीआई का उपयोग मुख्य रूप से किया जा रहा है, इसलिए यह केवल एक क्लाइंट फ़ाइल से बना है।
db - डीबी के साथ संवाद करने के लिए तर्क परिभाषित किया गया है। connection के अंदर का कोड केवल कनेक्शन का प्रबंधन करता है, और repository में विभिन्न upsert SQL को निष्पादित करने के लिए तर्क हैं। कोड में SQL रखना बहुत जटिल है, इसलिए हम भविष्य में SQL को अलग फ़ाइल में रखने की योजना बना रहे हैं।
util - इसमें विभिन्न प्रकार के सहायक तर्क परिभाषित हैं जो कार्य करते समय उपयोग किए जाते हैं। error गो में उत्पन्न त्रुटि परिणामों को आसानी से संभालने के लिए अस्थायी रूप से बनाया गया एक स्क्रिप्ट है। जैसा कि आप बाद में विकास कहानी में देखेंगे, यह एक बड़ा बटरफ्लाई प्रभाव का कारण बनता है(?)
config फ़ाइल .env फ़ाइल पढ़ती है, और हम .env फ़ाइल पढ़ने के लिए कोई अलग पैकेज नहीं उपयोग कर रहे हैं, इसलिए हमने .env फ़ाइल पढ़ने के लिए एक फ़ंक्शन को स्वयं परिभाषित किया है।
worker - इसमें मुख्य तर्क है जो api और db तर्क का उपयोग करके वांछित क्रिया को लागू करता है। अगर भविष्य में वर्कर की संख्या बढ़ जाती है, तो यह भी बढ़ना चाहिए, लेकिन फिलहाल केवल एक मुख्य वर्कर क्रिया को शामिल किया गया है।
भविष्य में, हम लेयर्ड आर्किटेक्चर के सिद्धांतों का पालन करते हुए कोड को विकसित करने की योजना बना रहे हैं।
प्रोजेक्ट निर्भरताएँ
पोस्टग्रेस का उपयोग करने के लिए pq
क्वेरी का उपयोग करने के लिए sqlx
वर्कर का समापन
सिर्फ सिद्धांतों को सूचीबद्ध करना थोड़ा उबाऊ लग सकता है, और मुझे भी थोड़ा नीरस लग रहा है, इसलिए मैं इसे थोड़ा जल्दी खत्म कर रहा हूँ।
भाग 2 पहले ही खत्म हो गया है। मुझे उम्मीद है कि भाग 3 से, मैं कोड की कुछ पंक्तियाँ शामिल करूँगा और चर्चा करूँगा।
लेगिनोट के विकास के दौरान, यदि आपको कोई ऐसी सुविधा की आवश्यकता है जो आपको लगती है कि होनी चाहिए, या यदि आपके मन में विकास के बारे में कोई प्रश्न है, तो कृपया बेझिझक टिप्पणी करें!
टिप्पणियाँ0