- LegiNote Projet de développement d'histoire 1 - Idée
- StatPan a lancé le projet LegiNote dans le but d'améliorer l'accessibilité aux projets de loi et aux procès-verbaux du Parlement et d'accroître l'efficacité législative grâce à l'IA.
Bonjour, je suis StatPan.
J'écris sur le développement du projet secondaire LegiNote.
Veuillez consulter le lien suivant pour la partie précédente.
Architecture de base
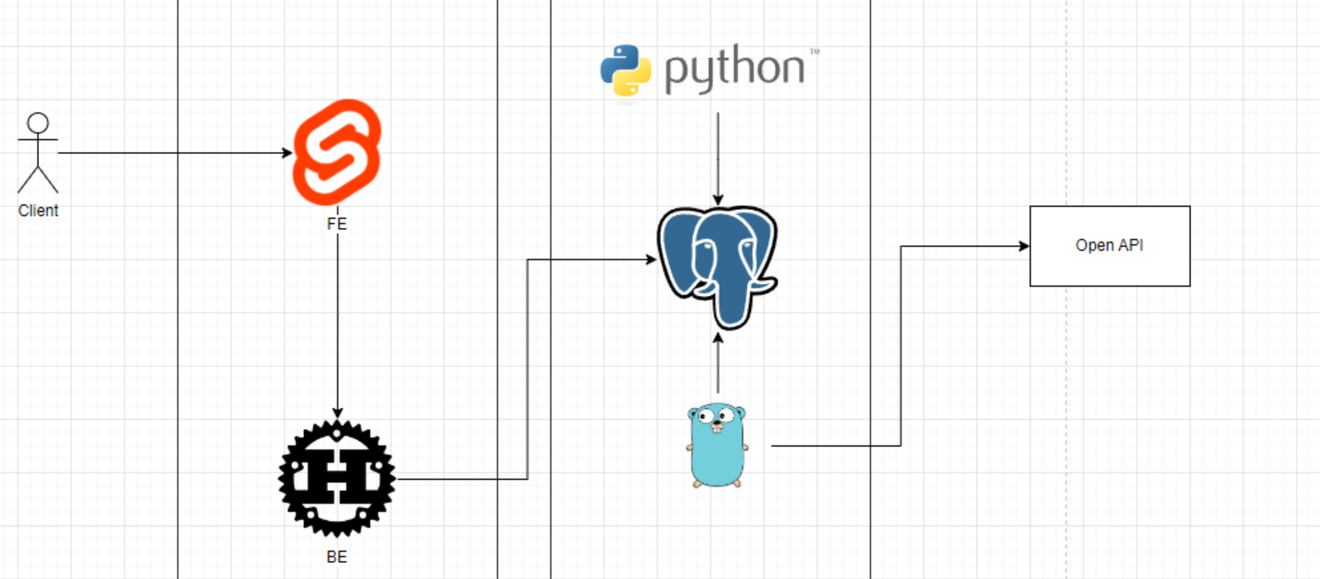
Conception de Leginote, gracieuseté de TaeYangTokki
Leginote est conçu pour être un service Web et utilisera la pile technologique suivante.
Front-end : Svelte
Back-end : Rust (nous envisageons sérieusement rupring, mais cela pourrait changer)
Worker : Go (nous visons une utilisation extrême de std, à l'exception des dépendances obligatoires)
Analyse de données : Python (du prétraitement à l'intégration future de l'intelligence artificielle)
Parmi ces piles technologiques, je prévois de publier une série d'articles sur le développement axé sur les parties Worker et Analyse de données, domaines dans lesquels je contribue principalement.
Commençons par parler du Worker.
Worker
Choix du langage

logo golang
J'ai commencé à programmer avec Python, et étant donné que mon travail principal est dans le domaine de la science des données, je suis le plus à l'aise avec ce langage. Cependant, ne connaissant que les langages de script, j'ai développé une envie de langages compilés robustes, ce qui m'a amené à m'intéresser à Go et Rust.
Plus précisément, le langage qui m'a le plus intéressé ces derniers temps est Rust, souvent mentionné aux côtés de C++ et Golang. (Bien que C++ soit un excellent langage, nous l'avons exclu du développement de services réseau dans ce projet. À l'avenir, je ne sais pas si nous l'utiliserons directement, sauf si nous devons gérer l'intérieur d'un framework d'apprentissage profond.)
J'ai donc appris Rust et Golang, et en les utilisant pour des requêtes réseau simples, j'ai pu identifier brièvement leurs avantages et inconvénients. Il serait trop long de les comparer ici, il est donc préférable de les résumer dans un autre article. En bref,
dans le domaine du réseau, pour une configuration sans dépendance supplémentaire et pour un projet inconnu dont la rentabilité est incertaine,Golanga été choisi.
Rôle du Worker
Écran OpenAPI
Le rôle du Worker est de collecter et de mettre à jour les données via le site OpenAPI à intervalles réguliers. Il peut être divisé en trois parties :
1. Configuration de la logique de collecte pour des informations spécifiques
2. Configuration du lanceur qui exécute la logique de collecte
3. Chargement des données collectées dans la base de données
L'objectif est d'étendre cette approche en appliquant les trois étapes ci-dessus de manière identique à diverses données d'API.
Méthode de structuration du projet
Il existe différentes architectures pour structurer un projet, et l'utilisation d'un framework permet de démarrer avec une structure prédéfinie. Cependant, comme mentionné précédemment, l'objectif de ce projet est de minimiser les dépendances, nous avons donc cherché à séparer les dossiers par fonction, afin de les rapprocher de la logique définie.
Le projet est structuré comme suit :
leginote-worker-bill/
├── main.go
├── api/
│ └── client.go
├── db/
│ ├── connection.go
│ └── repository.go
├── util/
│ ├── error.go
│ └── runner.go
│ └── config.go
├── worker/
│ └── worker.go
├── go.mod
└── go.sum
api - La collecte de données s'effectue via l'OpenAPI de données publiques. Par conséquent, le code de base pour communiquer avec l'OpenAPI est placé dans le dossier api. Actuellement, un seul API est utilisé en tant que principal, donc la structure est constituée d'un seul fichier client.
db - La logique de communication avec la base de données est définie ici. Le code interne de connection ne gère que la connexion, tandis que repository contient la logique d'exécution de diverses requêtes SQL upsert. Le fait que le code contienne directement du SQL est complexe, nous prévoyons donc de créer un fichier distinct pour le SQL ultérieurement.
util - Il s'agit d'un endroit où diverses logiques auxiliaires sont définies lors de l'exécution des tâches. error est un script temporaire créé pour faciliter le traitement des résultats d'erreurs de Go. Comme vous le verrez plus tard dans les développements futurs, cela aura un effet papillon énorme (?)
Le fichier config définit une fonction de lecture de fichier .env, car nous ne voulons pas utiliser de package distinct pour lire les fichiers .env.
worker - Il contient la logique principale qui utilise les logiques api et db de manière appropriée pour produire le comportement souhaité. Si le nombre de Workers augmente à l'avenir, il faudra également les augmenter, mais pour l'instant, seul le comportement du Worker principal est inclus.
À l'avenir, nous prévoyons de faire évoluer le code en maintenant les principes de l'architecture en couches.
Dépendances du projet
pq pour l'utilisation de Postgres
sqlx pour l'utilisation de requêtes
Fin du Worker
Énumérer la théorie sans code est peut-être ennuyeux, et je trouve que je commence à m'égarer un peu, donc je vais conclure rapidement.
La partie 2 est déjà terminée. J'espère pouvoir inclure plus de code dans les parties suivantes pour rendre les explications plus intéressantes.
N'hésitez pas à laisser un commentaire si vous avez des fonctionnalités que vous souhaitez voir apparaître dans LegiNote ou si vous avez des questions sur le développement !
Commentaires0